~hackernoon | Bookmarks (2032)
-
Ethereum L2 Taiko And DoraHacks Are Launching The Largest Anonymous Community Vote In Crypto History
Taiko and DoraHacks are spearheading the biggest anonymous community vote ever conducted in Web3. The initiative...
-
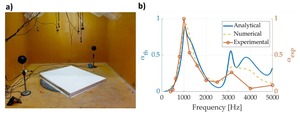
How This Acoustic Panel Performed in a Real-World Sound Test
A 3D-printed acoustic panel was tested in a reverberation room using ISO 354 standards. Results showed...
-
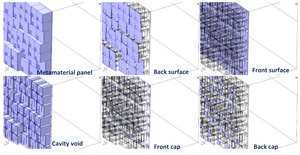
The Science of Soundproofing: A Look at 3D-Printed Acoustic Panels
A noise-absorbing panel was fabricated using selective laser sintering (SLS) to achieve precise labyrinthine structures. Additional...
-
The TechBeat: Win Up to $2000 in the #blockchain Writing Contest by Aleph Cloud and HackerNoon (2/9/2025)
How are you, hacker? 🪐Want to know what's trending right now?: The Techbeat by HackerNoon has...
-
The HackerNoon Newsletter: So.. How Does One REALLY Determine AI Is Conscious? (2/8/2025)
How are you, hacker? 🪐 What’s happening in tech today, February 8, 2025? The HackerNoon Newsletter...
-
Dealing With an Aggressive Manager Is Simpler Than You Think
While aggressive managers are difficult, they aren’t impossible to work with. With the right strategies, you...
-
Remote Development Made Simple With DevPod - A Free, Open-Source Tool
In this introductory blog post, I showed a small fraction of what you can do. I...
-
HackerNoon Decoded 2024: Celebrating Our Tech Stories Community!
Welcome to HackerNoon Decoded—the ultimate recap of the Tech Stories, writers, and trends that defined 2024!...
-
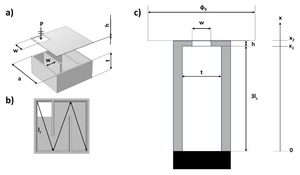
Can 3D Printing Improve Soundproofing? This Study Says Yes
Researchers tested 3D-printed labyrinthine unit cells using an impedance tube to measure sound absorption efficiency (100-5000...
-
Shhh! The Future of Noise Control Is Twisting Through 3D-Printed Labyrinths
Researchers developed a 3D-printed noise-absorbing panel using labyrinthine metamaterials. The design leverages space-coiling structures to enhance...
-
Democratizing Access to AI Has Become More Important Than Ever
Artificial Intelligence (AI) is no longer a futuristic concept confined to research labs and high-tech corporations....
-
So.. How Does One REALLY Determine AI Is Conscious?
Since language is connected with human carbon-based consciousness, and AI has a conversational and relatable language...
-
Biohackers Say They Have Cracked the Code to Producing Healthier Babies
Personal genotyping can illuminate what you might be doing wrong in the fertility optimization department. This...
-
How 3D-Printed Sound Panels Can Absorb Noise More Efficiently
Researchers analyzed labyrinthine unit cells using a first-iteration Wunderlich curve design, modeling thermo-viscous losses to optimize...
-
The TechBeat: Your Chatbot Isn’t Reading Words—It’s Counting Tokens (2/8/2025)
How are you, hacker? 🪐Want to know what's trending right now?: The Techbeat by HackerNoon has...
-
Media Slant: Slant Contagion and Polarization
Here, we replicate Table 4, but instead of pre-FNC/MSNBC era newspaper endorsements, we distinguish observations by...
-
Are the Effects of Contagious Media Slant Driven by Supply or Demand?
A relevant question is whether the effects of contagious slant are driven by supply or demand...
-
Researching Media Slant: Language Features and Topics
In Table C.14, re-run our main specification, but instead of bigram-based similarity with FNC, we regress...
-
Let's Take a Look at Fox News Channel's Viewership
In our quest to study media slant, let's take a look at Fox News Channel's viewership.
-
Cable News' Effects on Newspaper Content: A Deeper Insight
Taking a deeper look at Cable news's effect on newspaper content.
-
Media Slant Research: Newspaper-County Observations
Here, we replicate the baseline estimates but only consider newspaper-county observations where the county coincides with...
-
Media Slant: The Relationship Between the FNC Channel Position and Local Newspaper Content
Figure C.4 visualizes the reduced form relationship between the FNC channel position and local newspaper content...
-
Researching Media Slant: A Peek At Our OLS Results
Table C.4 shows OLS results for regressions of predicted Fox News similarity newspaper Slant on TV...
-
HackerNoon vs Bitcoin - The Ultimate Showdown You Didn't Ask For
I explore with simplistic mathematical models to help me, how HackerNoon stacks up against Bitcoin, the...